
Programming a Python tool to get HTTP status codes in bulk
For the past few months, I’ve been investigating a network of websites used for scamming. I’ll have a separate write up once it’s complete, but during that investigation, I needed a quick way to iterate through a list of domains to identify which ones were active and which ones were not. I could have researched and learned a tool written by another author, but it sounded like a simple and fun project to write a tool myself. I know Python, so I’ll be writing the script using that language.
Requirements
Before I start writing code, it’s helpful to outline what the tool needs to accomplish and how it will accomplish it.
- Must be able to take a list of domains as input
- Ideally, I want to process a list of domains at the command line with a single command.
- The easiest way to accomplish this is with a CSV file
- Must provide output that can be quickly referenced and indicates the status of each domain
- I don’t want to copy+paste or do any transferring of data between documents once the command has been run. The output should be ready to use as soon as the program is done.
- Must not modify the the list provided to it
- If I need to run to tool using the same list of domains more than once, it would speed up the process significantly if the list used as input is not modified.
Constraints and scope
There are practically endless possibilities to make the planned tool robust enough to handle many different scenarios. However, for the sake of simplicity and time, I want to keep this project within a narrow scope.
- Formatting of the input
- Since I don’t plan to release or support the tool for the general public, the acceptable formatting of the input CSV file is rigid. The tool will only support a single column of domains, with one domain per row, and no header row.
- Relatively immature error handling
- I may improve error reporting in a future iteration, but the list for which I built this tool has perfectly uniform domains that work consistently with the request module. Error reporting is not a significant focus.
- Few options
- Since I am building this tool with a solitary list in mind, I have a good idea of the arguments I’ll need to build up front (input and output) and those that aren’t necessary in this iteration.
Modules
Based on the requirements of the project, I need a few capabilities that aren’t included in Python by default. For those, I’ll use built-in modules.
- requests
- Handles HTTP requests
- argparse
- Allows for the specification of arguments. Specifically, program users need to specify input and output file paths
- csv
- Since I’m handling input and output in CSV files, I’ll use the csv module to handle reading from and writing to CSVs.
- shutil
- A module for file operations, shutil will allow me to create a copy of the input file to satisfy the non-mutable input requirement.
import requests
import argparse
import csv
import shutilConfiguring arguments
There are only two arguments that a user can specify in the first iteration of the program: input file path and output file path. I’ll do this using the argparse module. Before I can configure either argument, argparse requires me to create an ArgumentParser object. I’ve stored it in a variable called “parser”.
parser = argparse.ArgumentParser(description='Request HTTP response codes for a list of domains.')From this object, I can call the add_argument() method each time I’d like to create an argument. I’ll allow the flags -i or –input and -o or –output. Then, I’ll provide a brief help description for each of them.
parser.add_argument('-i', '--input', help='The file for the program to use')
parser.add_argument('-o', '--output', help='The destination of the output file')Last, I need to tell the ArgumentParser object to parse the arguments with the parse_args() method. This tells ArgumentParser to inspect the command line, convert arguments to the proper type, then take the proper action for each of them. It’s assigned to a variable I’ve called “args” so that I can call it’s arguments later.
args = parser.parse_args()Copying the input file
Since I may want to run the program multiple times using the same list of domains, I don’t want to modify the list when the program runs. As a result, I’ll create a copy of the list to be modified. To do so, I use the function copyfile() from the shutil module. The function takes two arguments: the path of the file to be copied and the path to where the file should be copied.
Since those paths are defined by the user as command line arguments, I can call the attributes of “args” that I created when configuring the arguments.
shutil.copyfile(args.input, args.output)Creating csv reader and writer objects
Now that I’ve got arguments and a copy of our input will be created, it’s time to crack open the CSVs. First, I need to create a csv object containing the file to be read from. This can be done with the built-in open() function, where the first parameter is the file to be opened. I’m loading data from the original list in args.input, not the copy args.output made during the previous section because I don’t want to read and write from the same file at the same time. I ran into some I/O errors trying to do that.
domainList = open(args.input)The csv module reads and writes using two different objects, called reader and writer objects, respectively. They’re created using the csv.reader() and csv.writer() methods. I need one of each, but since args.input will only be used for reading, I’m setting up the reader object first.
domainReader = csv.reader(domainList)I’m set up to read from the file! Great! Next, I need to set up the ability to write to the output file. The process is almost identical. I’m using the open function again, but this time I’m opening the file in write mode with parameter ‘w’. Additionally, I’m adding the parameter newline=” to prevent double spacing in my output. Then I’m loading that csv object into a writer object.
domainListWrite = open(args.output, 'w', newline='')
outputWriter = csv.writer(domainListWrite)Iterating through the list
Now that I can read from my input file and write to my output file, I can create the logic to handle each domain. I’ll do this using a for loop. Since a reader object is organized as a list of lists corresponding to the matrix of a spreadsheet, and since there’s one domain per line in my input, I can simply iterate row by row until the list is exhausted.
for row in domainReader:To start off the loop, I need to set up a try, except, else statement. First, I’m going to try the get() function from the requests module to issue an HTTP request to the domain in the row being iterated upon. Remember that the reader is a list of lists, so I’ve already identified the first list (the row in the for statement), but I have to identify the second list (or column) by index. In my input spreadsheet, the domains are in the first, left-most column so I’m using row[0]. The get() function requires string input, so I wrap it in the str() function.
Put together and assigned to variable x, I’ve created a response object. This is the logic that issues the HTTP request to each web server.
try:
x = requests.get(str(row[0]))It’s necessary to put that code in a try statement because of the way the requests module handles unreachable hosts. If a web server is unreachable, it can’t issue a status code. That becomes a problem if I try to add a status code to my output when it doesn’t exist. As a result, I’ll create an exception to basically say “if you can’t reach the web server, just print Unreachable instead of a status code”.
except:
outputWriter.writerow([row[0], "Unreachable"])Last in the for loop, I need to create behavior that writes the status code when the get() method can reach the web server. I do this with an else statement. The written status code is accessed via the status_code attribute of the response object.
else:
outputWriter.writerow([row[0], str(x.status_code)])With these lines, the meat and potatoes of the program are finished. I can close the for loop.
Finishing up
Now that the program is done reading and writing to the csv files, I need to close the files using the close() method. Note that I’m not closing the reader or writer objects, but the files that were loaded into those objects instead.
domainList.close()
domainListWrite.close()Testing
It’s very easy to test the script to make sure it works. I’ve created a simple list of domains in csv format, of which the status codes are known to me.
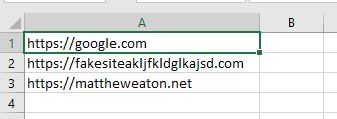
I’ve saved the script as statusCodes.py and placed my input list in the same directory. I can run it by opening cmd, changing directory to the location I saved the script, and entering the following command:
python statusCodes.py domains.csv domainsOutput.csvThe script has created domainsOutput.csv in the directory where it was run. It contains the same list of domains, but in column B you can see the status code or excepted “Unreachable”. Success!
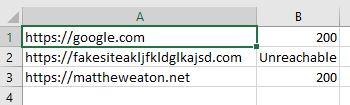
Since I wrote this script quickly to accommodate a known list, I didn’t put the bells or whistles on it. It’s quite rudimentary, and I can immediately think of some ways it can be improved. However, it satisfies it’s purpose, and it will certainly save me time during my investigations.
The final product
import requests
import argparse
import csv
import shutil
parser = argparse.ArgumentParser(description='Request HTTP response codes for a list of domains.')
parser.add_argument('-i', '--input', help='The file for the program to use')
parser.add_argument('-o', '--output', help='The destination of the output file')
args = parser.parse_args()
shutil.copyfile(args.input, args.output)
domainList = open(args.input)
domainReader = csv.reader(domainList)
domainListWrite = open(args.output, 'w', newline='')
outputWriter = csv.writer(domainListWrite)
for row in domainReader:
try:
x = requests.get(str(row[0]))
except:
outputWriter.writerow([row[0], "Unreachable"])
else:
outputWriter.writerow([row[0], str(x.status_code)])
domainList.close()
domainListWrite.close()